Introduction
Background
The Netherlands Biodiversity API (NBA) facilitates access to the Natural History Collection at the Naturalis Biodiversity Center. Next to than museum specimen records and metadata, access to taxonomic classification and nomenclature, geographical information, and to multimedia files is provided. By using the powerful Elasticsearch engine, the NBA facilitates searching for collection- and biodiversity data in near real-time. Furthermore, by incorporating information from taxonomic databases, taxonomic name resolution can be accomplished with the NBA. Persistent Uniform Resource Identifiers (PURLs) ensure that each species accessible via the NBA is represented by a citable unambiguous web reference. Access to our data is provided via a REST interface and several clients such as the BioPortal, a web application for browsing biodiversity data that is served by the NBA.
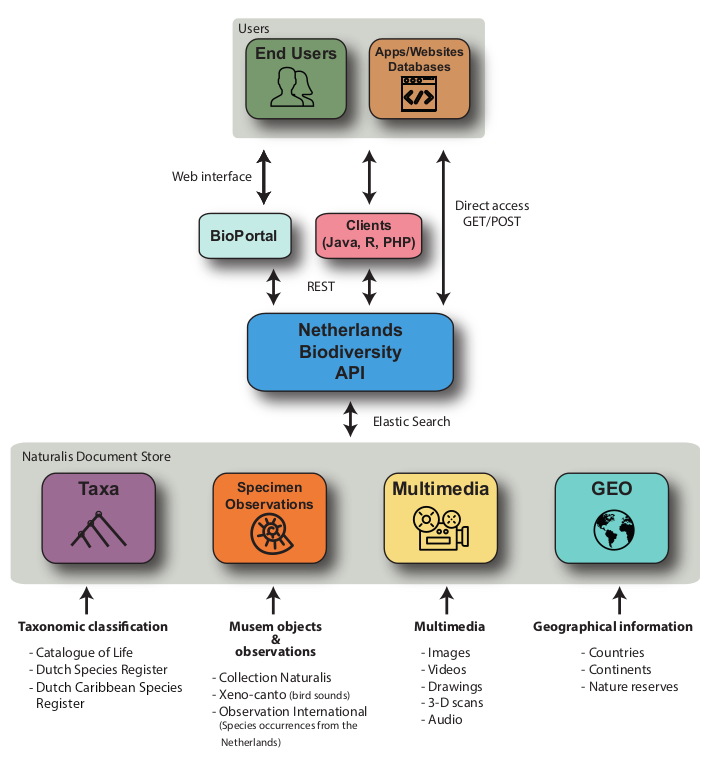
Available Data Types
The NBA provides access to four basic data types that are interlinked:
-
A Specimen record can represent a biological (botanical or zoological) or geological entity stored at Naturalis. In addition, sound records from the wildlife sound database Xeno-canto are also stored as specimen objects. Specimen data usually comprise information on reservation, identification, classification, taxonomy (see below), and details about the gathering/acquisition process of the specimen, such as geospatial information. Specimen data are harvested from two in-house collection registration systems for animal and plant specimens, and from the wildlife sounds database Xeno-canto (also hosted at Naturalis).
-
Taxonomic information about a biological entity is provided in Taxon the taxon data type, comprising hierarchy and placement in the Tree of Life, information on synonymy and the mapping to common (species) names in different languages. These data are taken from three taxonomic databases, the Catalogue of Life, the Dutch Species Register (NSR), a comprehensive classification of all species in the Netherlands, and the Dutch Caribbean Species Register, an overview of the biodiversity of Aruba, Bonaire, Curaçao, Saba, Sint Eustatius and Sint Maarten. Taxon and Specimen data types can be aggregated on fields such as scientific or common taxon names.
-
Multimedia data store images (such as photos, drawings or sonograms), videos, and sounds that are associated with Specimen and Taxon data. Data sources are our in-house collection registration systems, the wildlife sounds database Xeno-canto and the NSR.
-
Objects of type GeoArea refer to geographical regions coded as polygons in the GeoJSON format. The NBA thereby facilitates geographical searches such as searching for all specimens that were collected in a certain region, or, vice versa, retrieve the region (e.g. a specific nature reserve) where a specimen was found. Data sources are listed in the detailed service description.
Services Summary
The services provided by the NBA can be roughly categorised into the following categories:
-
Query services provide access to all indexed (and therefore searchable) fields within a data type. Simple queries can be written as human readable queries which means the query parameters are simply passed as URL parameters. Complex JSON queries provide a more powerful mechanism to access the data, since query terms can be nested, weighted and/or filtered in a more sophisticated manner.
-
Data access services allow the access of specific fields within a data type. These fields are generally identifier fields. Note that all data access services are essentially query services for a certain value, implemented for a more convenient user experience.
-
Type specific metadata services give information about data type specific fields and settings. This includes information about available fields and paths and the supported operators for comparison.
-
General metadata services provide general information not specific to document types. This includes general settings and controlled vocabularies for certain field values.
-
Download services facilitate the bulk retrieval of query results as Darwin Core Archive(DwCA) files.
-
Aggregation services summarise a list of query results based on values that are shared for certain fields. Currently, this grouping is supported for specimen and taxon data types and the grouping is done on the scientific name.
A complete list of services can be found in the swagger_ui_link("API endpoint reference"). The table below lists the NBA's different service types and gives links to specific documentation resources and examples.
| Service type | Document type | |||
|---|---|---|---|---|
| Specimen | Taxon | GeoArea | Multimedia | |
| Query Query (advanced) |
Path: /specimen/query/ Service details Search fields Examples |
Path: /taxon/query/ Service details Search fields Examples |
Path: /geo/query/ Service details Search fields Examples |
Path: /multimedia/query/ Service details Search fields Examples |
| Data access | Service details Examples |
Service details Examples |
Service details Examples |
Service details Examples |
| Download (static) | Path: /specimen/dwca/getDataSet/ Service details Examples |
Path: /taxon/dwca/getDataSet/ Service details Examples |
not available | not available |
| Download (dynamic) | Path: /specimen/dwca/query/ Service details Examples |
Path: /taxon/dwca/query/ Service details Examples |
not available | not available |
| Metadata (data specific) | Path: /specimen/metadata/ Service details Examples |
Path: /taxon/metadata/ Service details Examples |
Path: /geo/metadata/ Service details Examples |
Multimedia: /multimedia/metadata/ Service details Examples |
| Metadata (general) | Path: /metadata/ Services details Examples |
|||
| Aggregation | Path: /specimen/groupByScientificName/ Service details Examples |
Path: /taxon/groupByScientificName/ Service details Examples |
not available | not available |
Access to Data
REST
The NBA is implemented as a RESTful API and can thus be accessed using standard REST clients or a web browser. For exploration or testing of the NBA services and/or PURL services we recommend using a command-line tool for transferring data as e.g. curl or a rest client browser plugin, e.g. the chrome rest client. A summary of available REST endpoints and data models present in the NBA can be found here.
API Clients
To provide programmatic access to the NBA, Naturalis plans to develop clients for several programming languages. These clients are build upon the NBA REST architecture and facilitate the integration of NBA access within scripts or software applications. Currently, clients for the following languages are available:
Bioportal
The Bioportal provides easy access via a web interface from which the user can browse and query the Naturalis collection data. The Bioportal makes use of (a part of) the NBA services to retrieve and display the data.